Submission status
Published
Submission Editor
Noah Carl
Title
A study of stereotype accuracy in the Netherlands: immigrant crime, occupational sex distribution, and provincial income inequality
Abstract
In this pre-registered study, we gathered two online samples totaling 615 subjects. The first sample was nationally representative with regards to age, sex and education, the second was an online convenience sample with mostly younger people. We measured intelligence (vocabulary and science knowledge, 20 items each) using newly constructed Dutch language tests. We measured stereotypes in three domains: 68 national origin-based immigrant crime rates, 54 occupational sex distributions, and 12 provincial incomes. We additionally measured other covariates such as employment status and political voting behaviors.
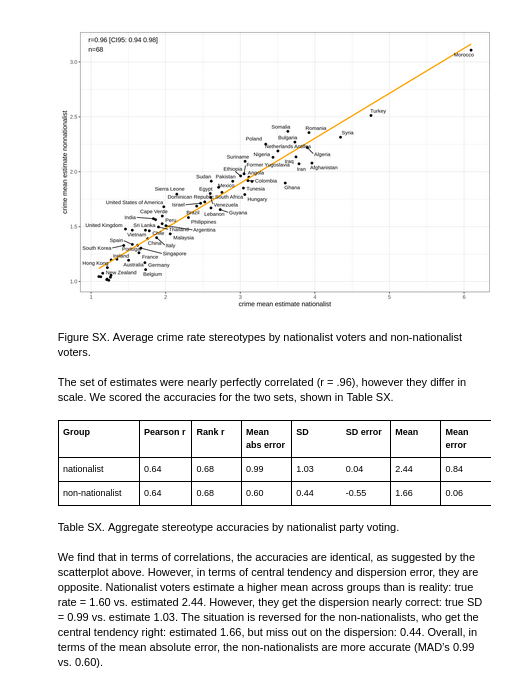
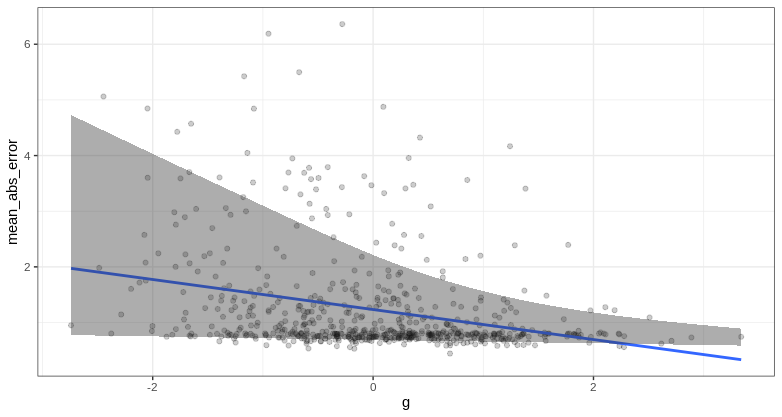
Results showed substantial stereotype accuracy for each domain. Aggregate (average) stereotype Pearson correlation accuracies were strong: immigrant crime .65, occupations .94, and provincial incomes .85. Results of individual accuracies found there was a weak general factor of stereotype accuracy measures, reflecting a general social perception ability. We found that intelligence moderately but robustly predicted more accurate stereotypes across domains as well as general stereotyping ability (r’s .20, .25, .26, .39, β’s 0.17, 0.25, 0.21, 0.37 from the full regression models). Other variables did not have robust effects across all domains, but had some reliable effects for one or two domains.
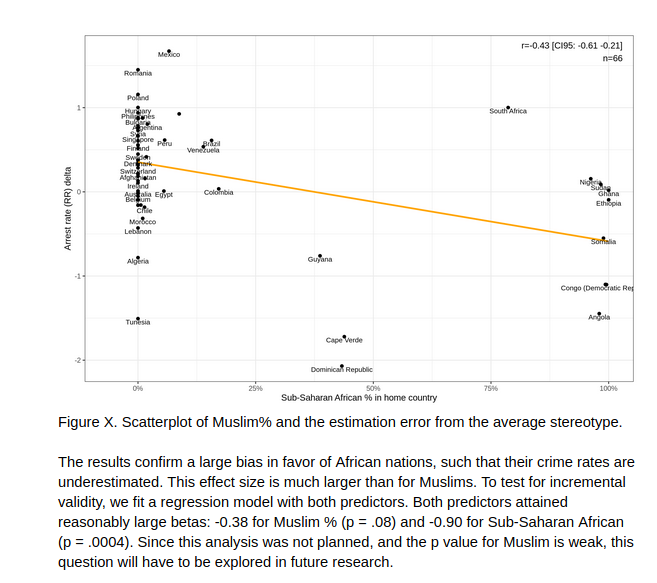
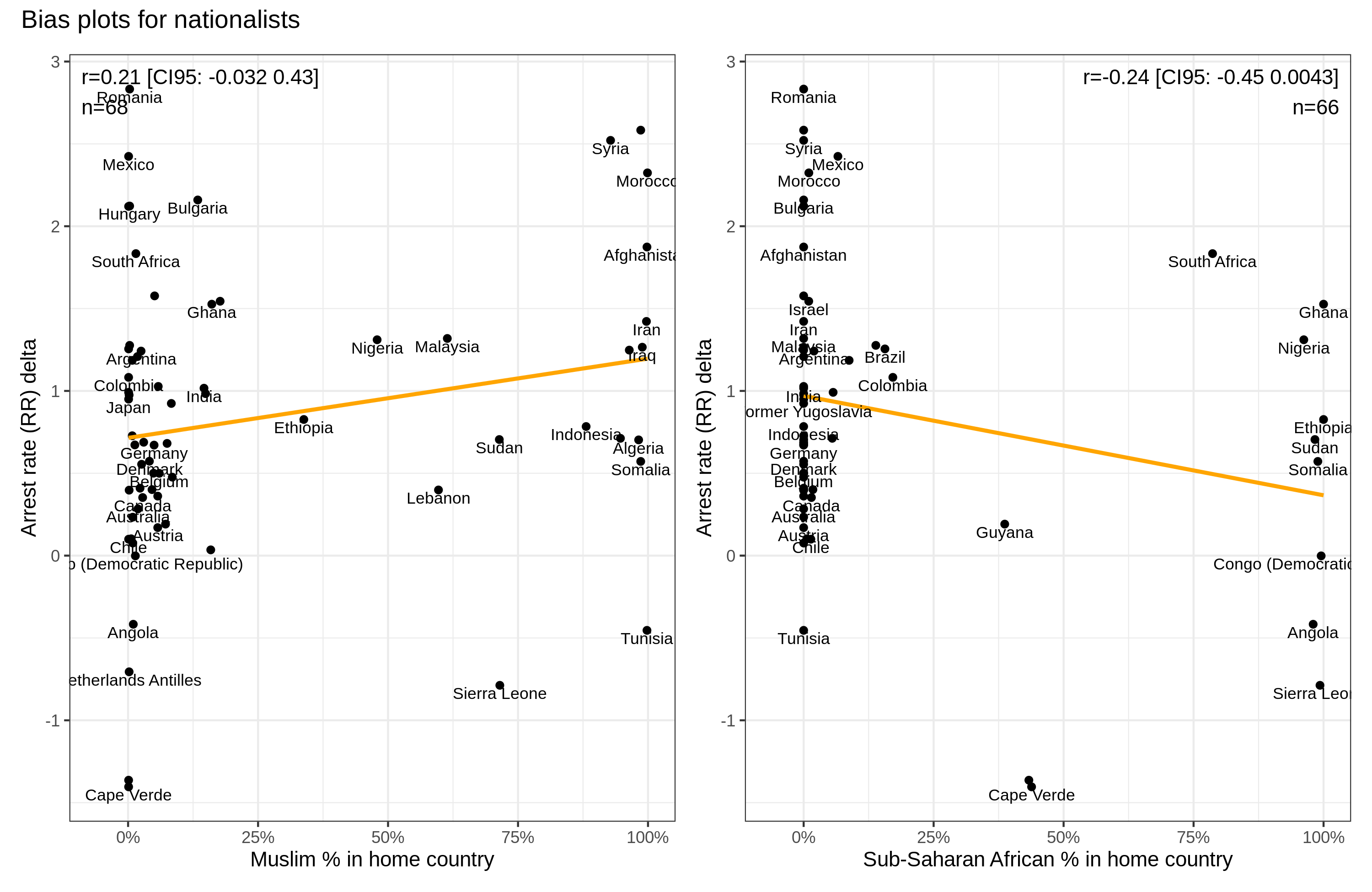
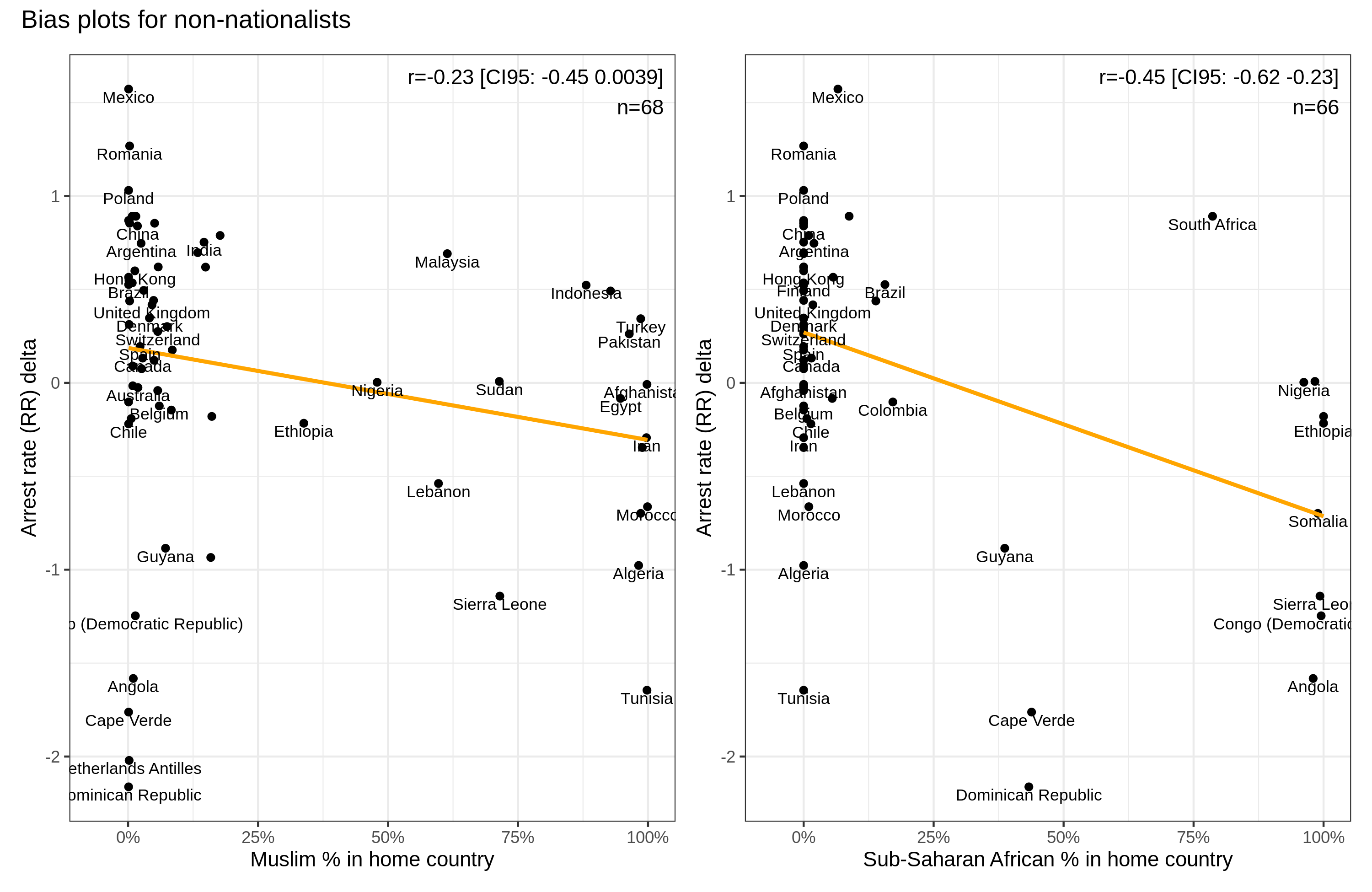
For immigrant crime rates, we also measured the immigration preferences for the same groups, i.e. whether people would like more or fewer people from these groups. We find that actual crime rates predict net opposition at r = .55, i.e., subjects were more hostile to immigration from origins that had higher crime rates. We examined a rational immigration preference path model where actual crime rates→stereotypes of crime rates→immigrant preferences. We found that about 84% of the effect of crime rates was mediated this way, and this result was obtained whether or not one included Muslim% as a covariate in the model. Overall, our results support rational models of social perception and policy preferences for immigration.
Keywords
intelligence,
cognitive ability,
stereotype accuracy,
immigrants,
inequality,
the Netherlands,
Islam,
immigration,
preregistered,
Muslim,
vocabulary,
science knowledge,
provinces,
gender,
sex
Supplemental materials link
https://osf.io/aexk9/
Planned Analyses
https://osf.io/8qhmr/
Peter Frost: Accept
Dr. g: Accept
Gerhard Meisenberg: Accept
Public Note
Dear reviewers, The paper is quite long, 21k words with references. This is because we decided to keep everything in a single paper instead of splitting it. Our questionnaire and set of planned analyses were many, so this resulted in the long, but hopefully, informative paper.