Submission status
Reviewing
Submission Editor
Emil O. W. Kirkegaard
Title
Mixed evidence for Lynn's developmental theory of sex differences using aptitude tests
Abstract
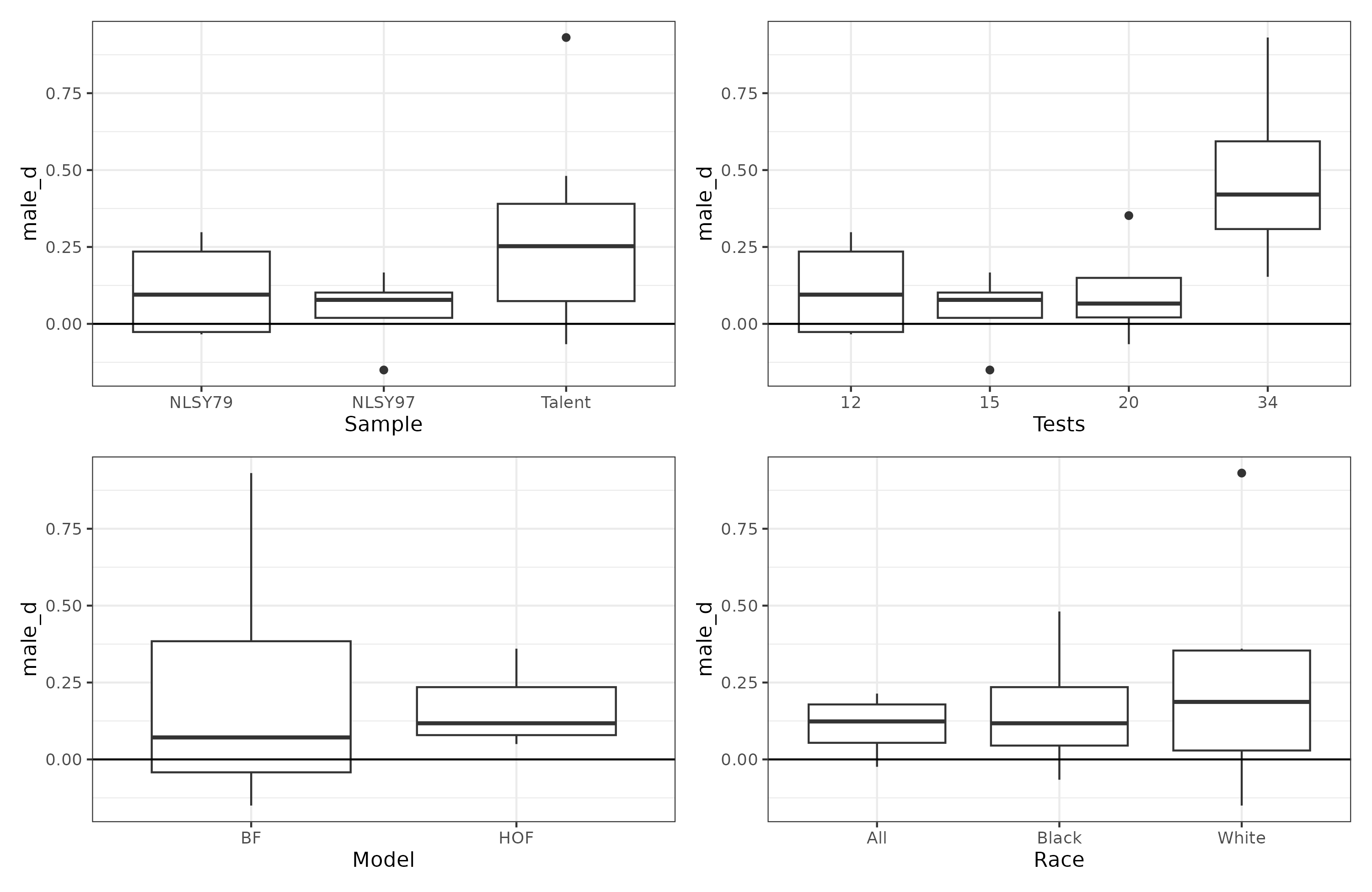
This study investigates sex differences in the general factor of intelligence and their interaction with age, using Multiple Group Confirmatory Factor Analysis (MGCFA). It aims at testing Lynn’s developmental theory of sex differences in intelligence, which states that the male advantage magnifies over the course of development, especially from age 16 onwards. The result provides some evidence for Lynn’s hypothesis in the NLSY79 and NLSY97 but not in the Project Talent. Results from the Higher Order Factor (HOF) model showed that in the NLSY79, the male advantage in g increases from 1.21 to 5.53 points in the entire sample, while in the NLSY97, the male advantage increases from 0.18 to 2.46 points in the entire sample. Similarly, results from the Bifactor (BF) model showed a greater increase in g scores across ages among males. However, the BF model often produced substantially different score gaps in g in all three datasets. This discrepancy between the HOF and BF models highlights the influence of test composition on latent scores. A sibling pair analysis in the NLSY datasets yielded ambiguous results. In the Project Talent, sex differences remained stable across ages 14-18 in the White sample, but a slight increase in female advantage was observed in the Black sample, contradicting Lynn’s hypothesis.
Keywords
IQ,
measurement invariance,
sex differences,
Spearman’s Hypothesis,
MGCFA,
aptitude tests
Supplemental materials link
https://osf.io/892e3/
Reviewer 1: Considering / Revise
Reviewer 2: Considering / Revise