Maybe a little bit, but at the same time, you requested a lot of very unreasonable things.
I said : "my R syntax maybe is not "elegant" to you, but produce correct results".
You said : "no it's bad I don't like it, and it's error prone, so you should modify it".
I respond : "your answer sound like you suspect me having made errors in typing the numbers; if so, check the numbers by yourself rather than continuing saying that the syntax is wrongdoing and bad".
It's not an exaggeration to say this whole discussion is pointless, and time-wasting. And I don't really want to waste time on something like this. Normally, these advices should be given elsewhere, e.g. "Other Discussions".
I did find an error in your code which affected the results. The error was directly caused by bad coding practices (hard-coding a variable instead of dynamically calculating the value). It is not unreasonable to insist on a good coding practice in that case. Others may want to re-do your analysis later, e.g. when more data becomes available. Or simply because they do not trust that you did correctly. Or because they want to apply the same analysis to a different dataset.
Another weird request is the figures. When I make a request about the shape and presentation of the article, it's not based on whether I like it or not. The way you usually cite references (i.e., [1], [2], [3] etc. instead of Kirkegaard et al. (2014) etc.) in all of your papers is very annoying to me, but I never said anything about it, because as I said, it's subjective, so it should not be a requirement. On the other hand, if I think the tables and figures would make problems for the credibility of the journal (e.g., using screenshot from blogpost) I will probably say it and it is a reasonable request. But concerning where I should put my figures, I decided this based on a certain logic : I never saw someone else doing as you requested. Either figures+tables are included within the text, or at the very end of the paper. The only reason you have given is because the figures are more important. I wonder in what way. Figure 8 and table 9 are equally important. Figure 8 only plots the parameter estimates given in table 9, where the depiction of the BW gap changes is already, and clearly visible (see column "Coeff. β1j").
You would do well to quote me, as I gave an explicit reason for this.
The figures are still not placed in the text. This means that the reader has to jump back and forth between the end of the paper and the text. You should move them up so they are near the text wherein they are discussed.
Since it apparently is so important to you, I will not hold my approval based on the placement of the figures. I will however not approve if the code syntax is placed in the paper instead of in the supplementary material.
You also said things that are very contradictional. Such as that we cannot tell from histogram if the distribution is normal or not. If it weren't you, I would say you're joking and try to play with my mind. In your blog post here, for example, you always accompany each Shapiro-Wilk test with histogram. Why, if you don't need histograms ? The reason is because you can't understand the numbers without graphical representations. I said it many times but you keep saying this. I have also the feeling you know you're wrong, but won't admit it. Otherwise, you wouldn't use graphs with SW test. The only reason why we can guess the extent of the non-normality with SW test is only because we had graphical representations about what a W value of <0.90, 0.95 or >0.99 might be. In fact, SW cannot be understood without histogram, but you don't need SW to understand a histogram. A single number like this is too abstract and it's not possible to understand the shape of the distribution of your data.
(You're looking for the word "contradictory".)
I did of course not say what you claim I said. It is a straw man. What I actually wrote is:
There is nothing wrong with the .99 guide. Your judgments based on Q-Q plots do not show much. Subjective judgments are bad in science (and everywhere else). If there is an objective way, use that instead.
Yes, there is deviation from normal. That is what W shows. Why are we disagreeing about? First you say .99 doesn't work even for large datasets. Then you agree that the two variables with .94-.95 show small to modest deviation from normality. Which way is it?
To recap again: Interpretation of histograms and QQ-plots is subjective. The SW value is objective (does not require any judgement call). As such, to decide whether or not normality is violated for a given sample, it is best to rely on an objective measure because for that reason there can be no disagreement. Of course, there can be disagreement about how to interpret the value of the SW test, but not the value itself. For large datasets (5k in my tests), W>.99 is a reasonable guide for normality.
Interpreting and using p-values from SW test is another matter, and I know that you like to criticize typical null hypothesis testing statistics. Perhaps read a textbook on Bayesian statistics and see if you like that more.
---
Quotes from previous posts.
Everything is wrong, if I can prove you I can get normal distribution with <0.99 W value. And I did.
You did not supply any normal distribution with <.99 W. You supplied various distributions clearly deviating from normal with W's <.99.
You even knew that the "universal" p-value cut off of 0.05 is arbitrary, but you are ready to believe that your value of W=0.99 is universal ? Probably not. Then, your guide is equally subjective. But if you don't believe W=0.99 is universal, why are you telling me that subjective judgments on QQ/histogram are bad ? It cannot be worse than using your guide, which would certainly prove most dangerous for me. Most researchers, if not all, would kill me if they learn that I use a rule applied to a statistic that has been recommended by someone who did not publish his paper on a peer-reviewed article. For a cut-off value of 0.99 so important in stats, it's clear that nobody will accept your judgment if it can't pass the peer-review. So, I have every reason to think that your suggestion to cite your blog post and follow your cut-off is extremely dangerous. And not a reasonable request.
If you quote a value as a guideline, cite something for it. I don't care if you cite my blog in particular. If you can find other useful simulations or expert advice, cite that.
I don't know how many times I should repeat it. Your comment assume you don't trust me, that is, you think I must have necessarily made a mistake somewhere. Why not rerun the syntax, if you want to see ? Like I've said, I examined the numbers many times before. Yes. Too many times.
I don't trust you to have done analyses correctly. It is not personal. I don't trust anyone to have done analyses correctly, including myself in previous studies (who has not found errors in their previous analyses when they looked through them at a later point?). Science must be open to scrutiny of the methods because everybody makes mistakes.
And it's not a bad code. Perhaps in a subjective way, but not in an objective way. A code is objectively "bad" or "wrong" only if it produces erroneous results. All of my results are correct.
Your results were slightly off as I already showed. It is bad code for the simply reason that you hard-coded a value instead of dynamically calculating it.
What do you mean by re-centering ? I centered, but I did not re-centered. I also don't understand "inputted values". If you mean imputed values, I didn't do anything like this. It seems you said it was the value 40.62 which was the problem. Once again, I said I'm not wrong. In my article, I said I have taken the mean age for people having wordsum score and I have also applied sampling weight for all of my analyses. See below :
"centering" or "re-centering" mean the same.
"inputted" is the past tense of "input", i.e. put in. Not imputation.
The value you wrote and used is wrong for the data you gave.
> mean(d$age)
[1] 41.47897I am using your syntax and the data you supplied.
This is not what I did. What is the purpose of [,1] here ?
Anyway, you're just showing me that I was right about R. No, R doesn't rock, it sucks. When you request fitted() without [,1] you will actually get the weird plot I had before. Like I've said, R is annoying. It sucks when you have missing data. Even when you correct for missing data, you still have problem, because you need to know first that fitted() must be used in conjunction with [,1]. You knew that, but I didn't. You'll never, never, never have this sort of problems in other softwares, where the procedure is straightforward. But R is silly.
Your code was wrong. The fitted() function returns a 2-column object. You only want to use column 1 for the plot, so you need to only extract that.
This mistake was easy to find, one can simply use head(), View() or dim() on the fitted object to see that it had the incorrect number of columns for the plot function.
I did not know it beforehand, I simply investigated the error. Most programming is bug fixing.
You didn't pay any attention to my syntax. Remember :
entiredata<-read.csv("GSSsubset.csv")
It's csv, not sav file. This means I have already converted my sav into csv file. It has no problem of factor variables because everything in csv files is numerical.
I did pay attention. Your code does not work because the datafile you supplied is in SAV format. So, one either needs to alter the code to load the SAV file (I tried that, as noted), or convert the file to CSV (better).
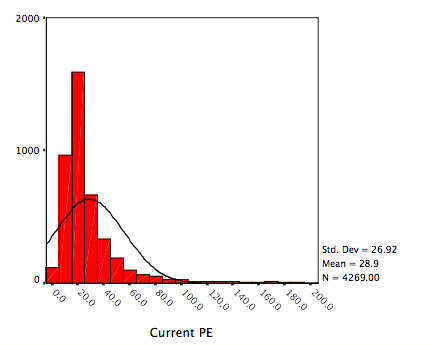
I left the best in the end. Try it several times. And if possible, try it many times. Now, I attach two graphs. sw1 and sw2. (EDIT : there is no title in the graphs. Anyway, sw1 is the graph on the left, attachment 577, and sw2 is on the right, attachment 578.) Most of the time, the above syntax generates something very to close sw1. But sometimes, you get something like sw2. You can tell by "eyeballing" that the two distributions are not alike. You will surely agree that most people can easily accept the sw1 as fairly normal, but you will surely also agree that most people won't accept the sw2 as normal, because of its high kurtosis.
The difference is caused because R has decided to use different numbers of breaks. This value is estimated from the data, so when you randomly generate data it sometimes arrives at another estimate. Specify the number to use in the hist() function. By my count, your left hist has 19 breaks while the right one has only 10. This gives the decidedly different look. It is just a visualization difference. In this case, it nicely illustrates my point because the difference changed your judgement regarding the normality even though it was about the same.
E.g. to run the code 1000 times:
shaps = numeric()
for (test in 1:1000){
x<-rnbinom(5000,7,.3)
#hist(x,breaks=50)
shap = shapiro.test(x)
shaps = c(shaps,shap$statistic)
}
sd(shaps)
mean(shaps)> sd(shaps)
[1] 0.003181278
> mean(shaps)
[1] 0.9658063So the W value is around .966. It fails the .99 guideline almost always (the highest value in my 1000 simulations was 0.9768483). Histograms with a proper number of breaks/bins show that it is decidedly non-normal (very long right tail, cut off left tail).
I attach as an example a few histograms with different numbers of breaks for the same data. (Note that the hist() function uses the breaks input as a suggestion and may fail to follow your advice. One can override this behavior if desired, but generally it is not necessary.)

{kind=link}
{kind=link}